The invention of the scientific journal in the 17th and 18th centuries helped create an institution that incentivizes scientists to share their knowledge with the entire world. But scientific journals were a child of the paper-and-ink media of their time. Scientific papers represent only a tiny fraction of the useful knowledge that scientists have to share with the world:
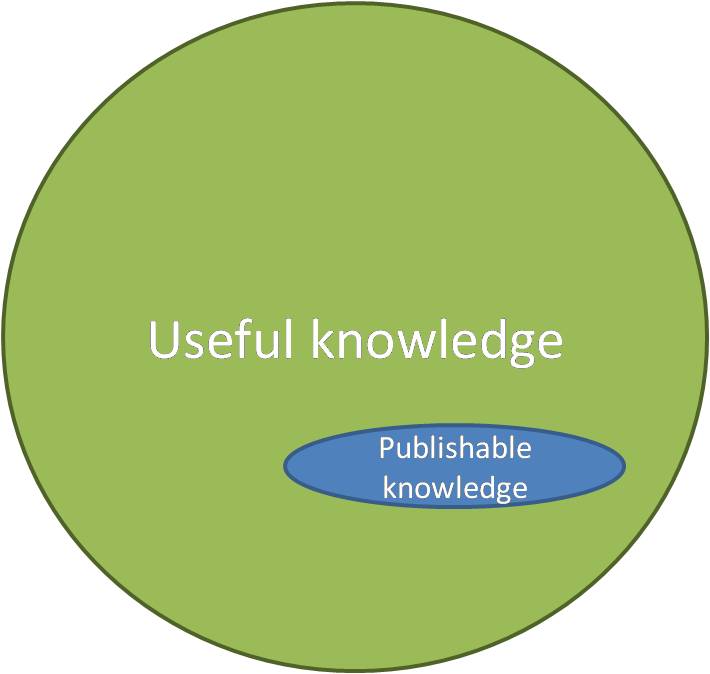
Enabled by a new media form, the internet, the last few years have seen a modest expansion in the range of knowledge that can be published and recognized by the scientific community:
The most obvious examples of this expansion are things like video and data.
However, there are many other types of useful knowledge that scientists have, and could potentially share with the world. Examples include questions, ideas, leads, folklore knowledge, notebooks, opinions of other work, workflows, simple explanations of basic concepts, and so on.
Each of these types of knowledge can be the basis for new online tools that further expand the range of what can be published by scientists:

It’s fun to think about what tools would best serve the needs associated with each type of knowledge. This is already starting to happen with tools and ideas like open notebook science, the science exchange, SciRate, and the Open Wetware wiki.
Some people will object that this kind of expansion is not desirable, that the last thing scientists need is an expansion in the range of information they deal with. Surely we are already overburdened?
Underlying this apparent problem is an opportunity to develop tools to assist scientists in finding relevant information, and to ensure that what they publish — their questions, ideas, and so on — is seen by those people who will most benefit. Ideally, the result will be not only a great expansion in the range of what is published, but also a great improvement in the quality of information that we encounter.
(This is, incidentally, a good argument in favour of strong open access, namely, that building high-quality information-finding tools will require open access to the entire scientific literature. In a gated web, Google Search and similar tools could not function, for they rely on the collective intelligence of the entire community of people publishing on the web. By accepting closed journals, scientists are condemning themselves to relatively low-quality information management tools.)
There are, of course, major cultural barriers to acceptance of these new tools. At present, there are few incentives to make use of new ideas like open notebook science. Why blog your ideas online, when someone else could be working on a paper on the same subject? This isn’t speculation, it’s already happening, and sometimes the blog posts are better – but try telling that to a tenure review committee.
What this means is that in addition to building new tools for each of these kinds of knowledge, we also need to provide ways of incentivizing the use of those tools, so scientists are motivated to move information out of their heads and labs, and onto the network, where it can catalyse new tools and new discoveries. This means measuring the contributions made with those new tools, and working on legitimizing those measures within the scientific community. This will take time, but it can be done. Visionary computer scientist Danny Hillis has pointed out that problems which seem impossible over two years are often trivial over fifty – I suspect this is how we’ll look back at the current changes going on in how science is done.
I’d like to distinguish between publishable knowledge and what you might call communicable knowledge. I think it’s worth preserving the word ‘publish’ for something that has been accepted by a peer-reviewed journal. There are a lot of correct things out there that one can do that shouldn’t be accepted by a good journal for any of a number of reasons, but may still be worth communicating. One can create venues for the latter sort, but I think it’s worth perhaps even strengthening the standards of the former.
And negative data: at least in biology, negative data have been pretty much unpublishable until a few (less than 5) years ago. Now there are a few outlets, like Nature Precedings (not peer reviewed) and BMC Proceedings (peer reviewed) that publish scientifically sound work that just don’t have any exciting results.
I have a lot of negative data myself, from trying things that seemed sensible on paper and then didn’t work out at the bench (and I figured out why). This happens quite often, and those experiments end up in people’s thesis but nowhere else, but the knowledge that “someone tried this and it didn’t work, because…” is VERY useful because it prevents others from making the same mistakes and would save a LOT of grant money wasted on reinventing the (square?) wheel.
I will add my usual rant on the subject. The current system rewards a hidden research agenda since you are only awarded credit once the the work is published in a peer reviewed journal. Since most research projects will take a few years (minimum) to complete, with many dead-ends explored, the chances that there is wasteful superpositions of efforts is very large. Even if the possible research space is huge (I assume) there is fashion in science too. On top of this there is a big pressure to publish, since this is almost the only way scientists are evaluated for career progression. Together this means that (in many fields) there is invariably someone else that you don’t know doing the same thing you are doing and it is mostly a matter luck or politics who gets to publish it first and get the credit. Confirming other people’s work receives very little, if any, credit.
So, open science is not just about increasing the amount of available information or structured computer readable data it is also about making the research agenda open to avoid the current waste of resources. Competition is useful but it should not waste years of research time, it should work on a finner level of detail, on figuring out the best experiments to prove a point.
Hi Eva,
Yes, it’d be great to be able to publish negative data more easily!
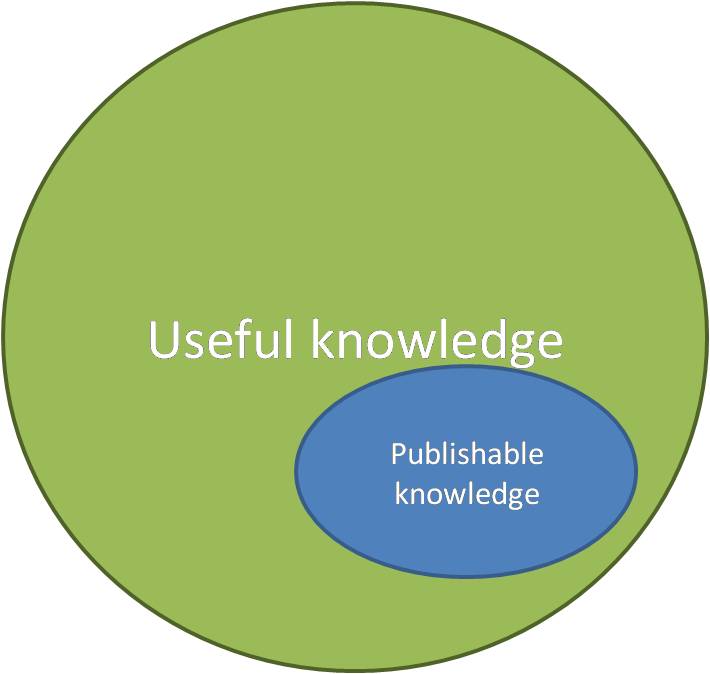
Of course there is a rather major assumption in all of your diagrams — that publishable knowledge in any model forms a subset of useful knowledge. I don’t think this has ever been true, but one of the drawbacks of easier publishability (which, I hasten to add, is a good thing) is that it also means that the realm of “that which is published but not useful” becomes much larger.
Michael – I considered expanding “publishable knowledge” beyond the border of “useful knowledge”, for exactly the reason you describe. I decided that instead of doing that it’d be more effective to discuss the problem explicitly in the text, in particular, the need for better tools for finding high quality work, and ignoring low quality work.
Re: Michael Albert’s comment I think we desperately need to get beyond the concept of ‘publishable’ (or worse ‘published’) = ‘true’. We often get this criticism when we talk about Open Notebook Science, particularly the idea we might expand it into undergraduate labs on live science projects. ‘But it might be wrong!’ is the objection. Well, yes, but so potentially is any piece of information. Filtering is crucial. Peer review is one type of filter. We need to develop other social, technical, and personal, filter systems to handle both the volume, characteristics, and quality of the data that is already overwhelming us.
But what I actually came here to comment on was;
Why blog your ideas online, when someone else could be working on a paper on the same subject? This isn’t speculation, it’s already happening, and sometimes the blog posts are better – but try telling that to a tenure review committee.
And this is why it is so important for those of us who are on tenure commitees or interview panels to ask questions about ‘other contributions’ and to encourage the people we mentor to include them. What we can’t expect is for young scientists to go into this like cannon fodder. Forging a scientific career is about taking risks but we have to support people through this.
Echoing Cameron’s thoughts on the category of “publishable”, I don’t think it is productive to categorize content using only boolean logic. This is especially true for the concept of “usefulness”. I don’t think the term has any meaning unless placed in a specific context.
By definition, any information unrelated to your current projects will be “useless”. Some of that information could be extremely useful to someone else.
In chemistry, this is particularly relevant for “failed” experiments. The “usefulness” of that information will be proportional to how closely it matches the search space of a researcher’s project and the quality of the data (raw and processed) provided to support observations and conclusions.
Making a lab notebook public is a simple and efficient way to make such information available to other researchers.
Nothing substantive to add, just cheering from the sidelines again. But man, does it do my tired postdoc heart good to read posts like this one. 🙂
Cameron – Yes, encouragement of younger people is critical.
I’m also interested in lobbying at the highest levels. A remarkably small number of people act as trendsetters for the rest of science, and this means cultural change can be relatively easy to accomplish. Just to pick one idea, if you could convince the US NIH and NSF to accept some type of “ScienceRank” as an (imperfect) quality measure for blog posts, then a lot of other institutions would follow quick smart. Witness the current stampede on open access policies.
Following up on Jean-Claude Bradley’s comment, one thing that excites me about open notebook science is that as the number of people involved increases, the quality of information returned by Google searches will quickly go up, benefiting from the collective intelligence of the entire community of people doing open notebook science.
In many ways it’d be nice to build a search engine targetted especially towards open notebook science. Done right it might increase the quality of the search results substantially beyond those returned by Google.
it’d be nice to build a search engine targetted especially towards open notebook science
As a first approximation, maybe try putting together a google custom search?
Bill – nice idea! I’ve never used Google Custom Search, but it looks like it’d be pretty easy to set up a centralized search page that indexed all open notebooks. Looks like opennotebookscience.com is still available if anyone wants to do this 🙂
Great points being brought up. The custom search engine for open notebooks was something I mentioned briefly in response to a post on Cameron’s blog on the science exchange and how we might get big players (e.g. Google) interested. There’s already Google Scholar, why not Google Scientist or Google Researcher, where the information that is potentially relevant isn’t necessarily in officially published material but in open notebooks, lab wikis, blogs, web forums, etc? Since the scope of potential sources is huge, a clever filtering system is important. And this isn’t limited to science either, so it might be an attractive business venture for a commercial search company.
Michael Barton has actually registered http://www.opennotebookscience.org/ but it is just an empty wiki at the moment because people have been too busy 🙂 We do need a web presence for this kind of thing.
why not Google Scientist or Google Researcher
That’s an excellent idea. I hope you’ll suggest it to everyone who’s going to SciFoo this year!
I’d love to see a ‘plus original research data’ button on google scholar that would add in all the relevant freely available research data.
And as Naom Harel pointed out over at my place we really don’t need more reasons (may require subscription to Nature) for making all the relevant raw data available.
oops, think I broke the link. It was to the editorial in Nature, date of 15 May 2008.
A Google Custom search is a very effective solution for what we are discussing. I use it to link to all UsefulChem content (blogs, wiki, server files, etc.) and put it at the top of the UC wiki front page:
http://usefulchem.wikispaces.com/
But this only works if there is a simple url access to the data (no logins of any type). I created a Custom Search called Open Notebook Science from ChemTools (Cameron), UsefulChem and Gus Rosania:
http://www.google.com/coop/cse?cx=013655027371052739584:_oiiv9wizdu
Type “protein” to give it a spin
Jean-Claude: Beautiful! It’d be great to put this somewhere people can see. Maybe at opennotebookscience.org?
Nice cartoon on Negative results at Vadlo website.
🙂