Part I: How Industries Fail
Until three years ago, the oldest company in the world was the construction company Kongo Gumi, headquartered in Osaka, Japan. Kongo Gumi was founded in 578 CE when the then-regent of Japan, Prince Shotoku, brought a member of the Kongo family from Korea to Japan to help construct the first Buddhist temple in Japan, the Shitenno-ji. The Kongo Gumi continued in the construction trade for almost one and a half thousand years. In 2005, they were headed by Masakazu Kongo, the 40th of his family to head Kongo Gumi. The company had more than 100 employees, and 70 million dollars in revenue. But in 2006, Kongo Gumi went into liquidation, and its assets were purchased by Takamatsu Corporation. Kongo Gumi as an independent entity no longer exists.
How is it that large, powerful organizations, with access to vast sums of money, and many talented, hardworking people, can simply disappear? Examples abound – consider General Motors, Lehman Brothers and MCI Worldcom – but the question is most fascinating when it is not just a single company that goes bankrupt, but rather an entire industry is disrupted. In the 1970s, for example, some of the world’s fastest-growing companies were companies like Digital Equipment Corporation, Data General and Prime. They made minicomputers like the legendary PDP-11. None of these companies exist today. A similar disruption is happening now in many media industries. CD sales peaked in 2000, shortly after Napster started, and have declined almost 30 percent since. Newspaper advertising revenue in the United States has declined 30 percent in the last 3 years, and the decline is accelerating: one third of that fall came in the last quarter.
There are two common explanations for the disruption of industries like minicomputers, music, and newspapers. The first explanation is essentially that the people in charge of the failing industries are stupid. How else could it be, the argument goes, that those enormous companies, with all that money and expertise, failed to see that services like iTunes and Last.fm are the wave of the future? Why did they not pre-empt those services by creating similar products of their own? Polite critics phrase their explanations less bluntly, but nonetheless many explanations boil down to a presumption of stupidity. The second common explanation for the failure of an entire industry is that the people in charge are malevolent. In that explanation, evil record company and newspaper executives have been screwing over their customers for years, simply to preserve a status quo that they personally find comfortable.
It’s true that stupidity and malevolence do sometimes play a role in the disruption of industries. But in the first part of this essay I’ll argue that even smart and good organizations can fail in the face of disruptive change, and that there are common underlying structural reasons why that’s the case. That’s a much scarier story. If you think the newspapers and record companies are stupid or malevolent, then you can reassure yourself that provided you’re smart and good, you don’t have anything to worry about. But if disruption can destroy even the smart and the good, then it can destroy anybody. In the second part of the essay, I’ll argue that scientific publishing is in the early days of a major disruption, with similar underlying causes, and will change radically over the next few years.
Why online news is killing the newspapers
To make our discussion of disruption concrete, let’s think about why many blogs are thriving financially, while the newspapers are dying. This subject has been discussed extensively in many recent articles, but my discussion is different because it focuses on identifying general structural features that don’t just explain the disruption of newspapers, but can also help explain other disruptions, like the collapse of the minicomputer and music industries, and the impending disruption of scientific publishing.
Some people explain the slow death of newspapers by saying that blogs and other online sources [1] are news parasites, feeding off the original reporting done by the newspapers. That’s false. While it’s true that many blogs don’t do original reporting, it’s equally true that many of the top blogs do excellent original reporting. A good example is the popular technology blog TechCrunch, by most measures one of the top 100 blogs in the world. Started by Michael Arrington in 2005, TechCrunch has rapidly grown, and now employs a large staff. Part of the reason it’s grown is because TechCrunch’s reporting is some of the best in the technology industry, comparable to, say, the technology reporting in the New York Times. Yet whereas the New York Times is wilting financially [2], TechCrunch is thriving, because TechCrunch’s operating costs are far lower, per word, than the New York Times. The result is that not only is the audience for technology news moving away from the technology section of newspapers and toward blogs like TechCrunch, the blogs can undercut the newspaper’s advertising rates. This depresses the price of advertising and causes the advertisers to move away from the newspapers.
Unfortunately for the newspapers, there’s little they can do to make themselves cheaper to run. To see why that is, let’s zoom in on just one aspect of newspapers: photography. If you’ve ever been interviewed for a story in the newspaper, chances are a photographer accompanied the reporter. You get interviewed, the photographer takes some snaps, and the photo may or may not show up in the paper. Between the money paid to the photographer and all the other costs, that photo probably costs the newspaper on the order of a few hundred dollars [3]. When TechCrunch or a similar blog needs a photo for a post, they’ll use a stock photo, or ask their subject to send them a snap, or whatever. The average cost is probably tens of dollars. Voila! An order of magnitude or more decrease in costs for the photo.
Here’s the kicker. TechCrunch isn’t being any smarter than the newspapers. It’s not as though no-one at the newspapers ever thought “Hey, why don’t we ask interviewees to send us a polaroid, and save some money?” Newspapers employ photographers for an excellent business reason: good quality photography is a distinguishing feature that can help establish a superior newspaper brand. For a high-end paper, it’s probably historically been worth millions of dollars to get stunning, Pulitzer Prizewinning photography. It makes complete business sense to spend a few hundred dollars per photo.
What can you do, as a newspaper editor? You could fire your staff photographers. But if you do that, you’ll destroy the morale not just of the photographers, but of all your staff. You’ll stir up the Unions. You’ll give a competitive advantage to your newspaper competitors. And, at the end of the day, you’ll still be paying far more per word for news than TechCrunch, and the quality of your product will be no more competitive.
The problem is that your newspaper has an organizational architecture which is, to use the physicists’ phrase, a local optimum. Relatively small changes to that architecture – like firing your photographers – don’t make your situation better, they make it worse. So you’re stuck gazing over at TechCrunch, who is at an even better local optimum, a local optimum that could not have existed twenty years ago:
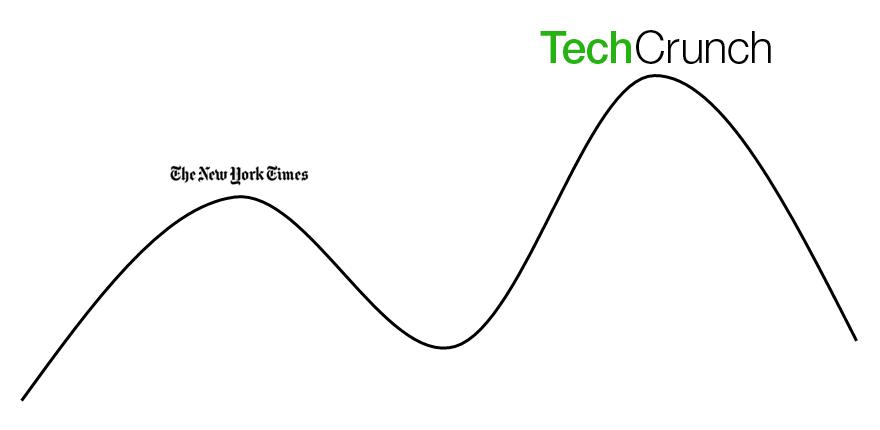
Unfortunately for you, there’s no way you can get to that new optimum without attempting passage through a deep and unfriendly valley. The incremental actions needed to get there would be hell on the newspaper. There’s a good chance they’d lead the Board to fire you.
The result is that the newspapers are locked into producing a product that’s of comparable quality (from an advertiser’s point of view) to the top blogs, but at far greater cost. And yet all their decisions – like the decision to spend a lot on photography – are entirely sensible business decisions. Even if they’re smart and good, they’re caught on the horns of a cruel dilemma.
The same basic story can be told about the dispruption of the music industry, the minicomputer industry, and many other disruptions. Each industry has (or had) a standard organizational architecture. That organizational architecture is close to optimal, in the sense that small changes mostly make things worse, not better. Everyone in the industry uses some close variant of that architecture. Then a new technology emerges and creates the possibility for a radically different organizational architecture, using an entirely different combination of skills and relationships. The only way to get from one organizational architecture to the other is to make drastic, painful changes. The money and power that come from commitment to an existing organizational architecture actually place incumbents at a disadvantage, locking them in. It’s easier and more effective to start over, from scratch.
Organizational immune systems
I’ve described why it’s hard for incumbent organizations in a disrupted industry to change to a new model. The situation is even worse than I’ve described so far, though, because some of the forces preventing change are strongest in the best run organizations. The reason is that those organizations are large, complex structures, and to survive and prosper they must contain a sort of organizational immune system dedicated to preserving that structure. If they didn’t have such an immune system, they’d fall apart in the ordinary course of events. Most of the time the immune system is a good thing, a way of preserving what’s good about an organization, and at the same time allowing healthy gradual change. But when an organization needs catastrophic gut-wrenching change to stay alive, the immune system becomes a liability.
To see how such an immune system expresses itself, imagine someone at the New York Times had tried to start a service like Google News, prior to Google News. Even before the product launched they would have been constantly attacked from within the organization for promoting competitors’ products. They would likely have been forced to water down and distort the service, probably to the point where it was nearly useless for potential customers. And even if they’d managed to win the internal fight and launched a product that wasn’t watered down, they would then have been attacked viciously by the New York Times’ competitors, who would suspect a ploy to steal business. Only someone outside the industry could have launched a service like Google News.
Another example of the immune response is all the recent news pieces lamenting the death of newspapers. Here’s one such piece, from the Editor of the New York Times’ editorial page, Andrew Rosenthal:
There’s a great deal of good commentary out there on the Web, as you say. Frankly, I think it is the task of bloggers to catch up to us, not the other way around… Our board is staffed with people with a wide and deep range of knowledge on many subjects. Phil Boffey, for example, has decades of science and medical writing under his belt and often writes on those issues for us… Here’s one way to look at it: If the Times editorial board were a single person, he or she would have six Pulitzer prizes…
This is a classic immune response. It demonstrates a deep commitment to high-quality journalism, and the other values that have made the New York Times great. In ordinary times this kind of commitment to values would be a sign of strength. The problem is that as good as Phil Boffey might be, I prefer the combined talents of Fields medallist Terry Tao, Nobel prize winner Carl Wieman, MacArthur Fellow Luis von Ahn, acclaimed science writer Carl Zimmer, and thousands of others. The blogosophere has at least four Fields medallists (the Nobel of math), three Nobelists, and many more luminaries. The New York Times can keep its Pulitzer Prizes. Other lamentations about the death of newspapers show similar signs of being an immune response. These people aren’t stupid or malevolent. They’re the best people in the business, people who are smart, good at their jobs, and well-intentioned. They are, in short, the people who have most strongly internalized the values, norms and collective knowledge of their industry, and thus have the strongest immune response. That’s why the last people to know an industry is dead are the people in it. I wonder if Andrew Rosenthal and his colleagues understand that someone equipped with an RSS reader can assemble a set of news feeds that renders the New York Times virtually irrelevant? If a person inside an industry needs to frequently explain why it’s not dead, they’re almost certainly wrong.
What are the signs of impending disruption?
Five years ago, most newspaper editors would have laughed at the idea that blogs might one day offer serious competition. The minicomputer companies laughed at the early personal computers. New technologies often don’t look very good in their early stages, and that means a straightup comparison of new to old is little help in recognizing impending dispruption. That’s a problem, though, because the best time to recognize disruption is in its early stages. The journalists and newspaper editors who’ve only recognized their problems in the last three to four years are sunk. They needed to recognize the impending disruption back before blogs looked like serious competitors, when evaluated in conventional terms.
An early sign of impending disruption is when there’s a sudden flourishing of startup organizations serving an overlapping customer need (say, news), but whose organizational architecture is radically different to the conventional approach. That means many people outside the old industry (and thus not suffering from the blinders of an immune response) are willing to bet large sums of their own money on a new way of doing things. That’s exactly what we saw in the period 2000-2005, with organizations like Slashdot, Digg, Fark, Reddit, Talking Points Memo, and many others. Most such startups die. That’s okay: it’s how the new industry learns what organizational architectures work, and what don’t. But if even a few of the startups do okay, then the old players are in trouble, because the startups have far more room for improvement.
Part II: Is scientific publishing about to be disrupted?
What’s all this got to do with scientific publishing? Today, scientific publishers are production companies, specializing in services like editorial, copyediting, and, in some cases, sales and marketing. My claim is that in ten to twenty years, scientific publishers will be technology companies [4]. By this, I don’t just mean that they’ll be heavy users of technology, or employ a large IT staff. I mean they’ll be technology-driven companies in a similar way to, say, Google or Apple. That is, their foundation will be technological innovation, and most key decision-makers will be people with deep technological expertise. Those publishers that don’t become technology driven will die off.
Predictions that scientific publishing is about to be disrupted are not new. In the late 1990s, many people speculated that the publishers might be in trouble, as free online preprint servers became increasingly popular in parts of science like physics. Surely, the argument went, the widespread use of preprints meant that the need for journals would diminish. But so far, that hasn’t happened. Why it hasn’t happened is a fascinating story, which I’ve discussed in part elsewhere, and I won’t repeat that discussion here.
What I will do instead is draw your attention to a striking difference between today’s scientific publishing landscape, and the landscape of ten years ago. What’s new today is the flourishing of an ecosystem of startups that are experimenting with new ways of communicating research, some radically different to conventional journals. Consider Chemspider, the excellent online database of more than 20 million molecules, recently acquired by the Royal Society of Chemistry. Consider Mendeley, a platform for managing, filtering and searching scientific papers, with backing from some of the people involved in Last.fm and Skype. Or consider startups like SciVee (YouTube for scientists), the Public Library of Science, the Journal of Visualized Experiments, vibrant community sites like OpenWetWare and the Alzheimer Research Forum, and dozens more. And then there are companies like WordPress, Friendfeed, and Wikimedia, that weren’t started with science in mind, but which are increasingly helping scientists communicate their research. This flourishing ecosystem is not too dissimilar from the sudden flourishing of online news services we saw over the period 2000 to 2005.
Let’s look up close at one element of this flourishing ecosystem: the gradual rise of science blogs as a serious medium for research. It’s easy to miss the impact of blogs on research, because most science blogs focus on outreach. But more and more blogs contain high quality research content. Look at Terry Tao’s wonderful series of posts explaining one of the biggest breakthroughs in recent mathematical history, the proof of the Poincare conjecture. Or Tim Gowers recent experiment in “massively collaborative mathematics”, using open source principles to successfully attack a significant mathematical problem. Or Richard Lipton’s excellent series of posts exploring his ideas for solving a major problem in computer science, namely, finding a fast algorithm for factoring large numbers. Scientific publishers should be terrified that some of the world’s best scientists, people at or near their research peak, people whose time is at a premium, are spending hundreds of hours each year creating original research content for their blogs, content that in many cases would be difficult or impossible to publish in a conventional journal. What we’re seeing here is a spectacular expansion in the range of the blog medium. By comparison, the journals are standing still.
This flourishing ecosystem of startups is just one sign that scientific publishing is moving from being a production industry to a technology industry. A second sign of this move is that the nature of information is changing. Until the late 20th century, information was a static entity. The natural way for publishers in all media to add value was through production and distribution, and so they employed people skilled in those tasks, and in supporting tasks like sales and marketing. But the cost of distributing information has now dropped almost to zero, and production and content costs have also dropped radically [5]. At the same time, the world’s information is now rapidly being put into a single, active network, where it can wake up and come alive. The result is that the people who add the most value to information are no longer the people who do production and distribution. Instead, it’s the technology people, the programmers.
If you doubt this, look at where the profits are migrating in other media industries. In music, they’re migrating to organizations like Apple. In books, they’re migrating to organizations like Amazon, with the Kindle. In many other areas of media, they’re migrating to Google: Google is becoming the world’s largest media company. They don’t describe themselves that way (see also here), but the media industry’s profits are certainly moving to Google. All these organizations are run by people with deep technical expertise. How many scientific publishers are run by people who know the difference between an INNER JOIN and an OUTER JOIN? Or who know what an A/B test is? Or who know how to set up a Hadoop cluster? Without technical knowledge of this type it’s impossible to run a technology-driven organization. How many scientific publishers are as knowledgeable about technology as Steve Jobs, Sergey Brin, or Larry Page?
I expect few scientific publishers will believe and act on predictions of disruption. One common response to such predictions is the appealing game of comparison: “but we’re better than blogs / wikis / PLoS One / …!” These statements are currently true, at least when judged according to the conventional values of scientific publishing. But they’re as irrelevant as the equally true analogous statements were for newspapers. It’s also easy to vent standard immune responses: “but what about peer review”, “what about quality control”, “how will scientists know what to read”. These questions express important values, but to get hung up on them suggests a lack of imagination much like Andrew Rosenthal’s defense of the New York Times editorial page. (I sometimes wonder how many journal editors still use Yahoo!’s human curated topic directory instead of Google?) In conversations with editors I repeatedly encounter the same pattern: “But idea X won’t work / shouldn’t be allowed / is bad because of Y.” Well, okay. So what? If you’re right, you’ll be intellectually vindicated, and can take a bow. If you’re wrong, your company may not exist in ten years. Whether you’re right or not is not the point. When new technologies are being developed, the organizations that win are those that aggressively take risks, put visionary technologists in key decision-making positions, attain a deep organizational mastery of the relevant technologies, and, in most cases, make a lot of mistakes. Being wrong is a feature, not a bug, if it helps you evolve a model that works: you start out with an idea that’s just plain wrong, but that contains the seed of a better idea. You improve it, and you’re only somewhat wrong. You improve it again, and you end up the only game in town. Unfortunately, few scientific publishers are attempting to become technology-driven in this way. The only major examples I know of are Nature Publishing Group (with Nature.com) and the Public Library of Science. Many other publishers are experimenting with technology, but those experiments remain under the control of people whose core expertise is in others areas.
Opportunities
So far this essay has focused on the existing scientific publishers, and it’s been rather pessimistic. But of course that pessimism is just a tiny part of an exciting story about the opportunities we have to develop new ways of structuring and communicating scientific information. These opportunities can still be grasped by scientific publishers who are willing to let go and become technology-driven, even when that threatens to extinguish their old way of doing things. And, as we’ve seen, these opportunites are and will be grasped by bold entrepreneurs. Here’s a list of services I expect to see developed over the next few years. A few of these ideas are already under development, mostly by startups, but have yet to reach the quality level needed to become ubiquitous. The list could easily be continued ad nauseum – these are just a few of the more obvious things to do.
Personalized paper recommendations: Amazon.com has had this for books since the late 1990s. You go to the site and rate your favourite books. The system identifies people with similar taste, and automatically constructs a list of recommendations for you. This is not difficult to do: Amazon has published an early variant of its algorithm, and there’s an entire ecosystem of work, much of it public, stimulated by the Neflix Prize for movie recommendations. If you look in the original Google PageRank paper, you’ll discover that the paper describes a personalized version of PageRank, which can be used to build a personalized search and recommendation system. Google doesn’t actually use the personalized algorithm, because it’s far more computationally intensive than ordinary PageRank, and even for Google it’s hard to scale to tens of billions of webpages. But if all you’re trying to rank is (say) the physics literature – a few million papers – then it turns out that with a little ingenuity you can implement personalized PageRank on a small cluster of computers. It’s possible this can be used to build a system even better than Amazon or Netflix.
A great search engine for science: ISI’s Web of Knowledge, Elsevier’s Scopus and Google Scholar are remarkable tools, but there’s still huge scope to extend and improve scientific search engines [6]. With a few exceptions, they don’t do even basic things like automatic spelling correction, good relevancy ranking of papers (preferably personalized), automated translation, or decent alerting services. They certainly don’t do more advanced things, like providing social features, or strong automated tools for data mining. Why not have a public API [7] so people can build their own applications to extract value out of the scientific literature? Imagine using techniques from machine learning to automatically identify underappreciated papers, or to identify emerging areas of study.
High-quality tools for real-time collaboration by scientists: Look at services like the collaborative editor Etherpad, which lets multiple people edit a document, in real time, through the browser. They’re even developing a feature allowing you to play back the editing process. Or the similar service from Google, Google Docs, which also offers shared spreadsheets and presentations. Look at social version control systems like Git and Github. Or visualization tools which let you track different people’s contributions. These are just a few of hundreds of general purpose collaborative tools that are lightyears beyond what scientists use. They’re not widely adopted by scientists yet, in part for superficial reasons: they don’t integrate with things like LaTeX and standard bibliographical tools. Yet achieving that kind of integration is trivial compared with the problems these tools do solve. Looking beyond, services like Google Wave may be a platform for startups to build a suite of collaboration clients that every scientist in the world will eventually use.
Scientific blogging and wiki platforms: With the exception of Nature Publishing Group, why aren’t the scientific publishers developing high-quality scientific blogging and wiki platforms? It would be easy to build upon the open source WordPress platform, for example, setting up a hosting service that makes it easy for scientists to set up a blog, and adds important features not present in a standard WordPress installation, like reliable signing of posts, timestamping, human-readable URLs, and support for multiple post versions, with the ability to see (and cite) a full revision history. A commenter-identity system could be created that enabled filtering and aggregation of comments. Perhaps most importantly, blog posts could be made fully citable.
On a related note, publishers could also help preserve some of the important work now being done on scientific blogs and wikis. Projects like Tim Gowers’ Polymath Project are an important part of the scientific record, but where is the record of work going to be stored in 10 or 20 years time? The US Library of Congress has taken the initiative in preserving law blogs. Someone needs to step up and do the same for science blogs.
The data web: Where are the services making it as simple and easy for scientists to publish data as it to publish a journal paper or start a blog? A few scientific publishers are taking steps in this direction. But it’s not enough to just dump data on the web. It needs to be organized and searchable, so people can find and use it. The data needs to be linked, as the utility of data sets grows in proportion to the connections between them. It needs to be citable. And there needs to be simple, easy-to-use infrastructure and expertise to extract value from that data. On every single one of these issues, publishers are at risk of being leapfrogged by companies like Metaweb, who are building platforms for the data web.
Why many services will fail: Many unsuccessful attempts at implementing services like those I’ve just described have been made. I’ve had journal editors explain to me that this shows there is no need for such services. I think in many cases there’s a much simpler explanation: poor execution [8]. Development projects are often led by senior editors or senior scientists whose hands-on technical knowledge is minimal, and whose day-to-day involvement is sporadic. Implementation is instead delegated to IT-underlings with little power. It should surprise no one that the results are often mediocre. Developing high-quality web services requires deep knowledge and drive. The people who succeed at doing it are usually brilliant and deeply technically knowledgeable. Yet it’s surprisingly common to find projects being led by senior scientists or senior editors whose main claim to “expertise” is that they wrote a few programs while a grad student or postdoc, and who now think they can get a high-quality result with minimal extra technical knowledge. That’s not what it means to be technology-driven.
Conclusion: I’ve presented a pessimistic view of the future of current scientific publishers. Yet I hope it’s also clear that there are enormous opportunities to innovate, for those willing to master new technologies, and to experiment boldly with new ways of doing things. The result will be a great wave of innovation that changes not just how scientific discoveries are communicated, but also accelerates the way scientific discoveries are made.
Notes
[1] We’ll focus on blogs to make the discussion concrete, but in fact many new forms of media are contributing to the newspapers’ decline, including news sites like Digg and MetaFilter, analysis sites like Stratfor, and many others. When I write “blogs” in what follows I’m usually referring to this larger class of disruptive new media, not literally to conventional blogs, per se.
[2] In a way, it’s ironic that I use the New York Times as an example. Although the New York Times is certainly going to have a lot of trouble over the next five years, in the long run I think they are one of the newspapers most likely to survive: they produce high-quality original content, show strong signs of becoming technology driven, and are experimenting boldly with alternate sources of content. But they need to survive the great newspaper die-off that’s coming over the next five or so years.
[3] In an earlier version of this essay I used the figure 1,000 dollars. That was sloppy – it’s certainly too high. The actual figure will certainly vary quite a lot from paper to paper, but for a major newspaper in a big city I think on the order of 200-300 dollars is a reasonable estimate, when all costs are factored in.
[4] I’ll use the term “companies” to include for-profit and not-for-profit organizations, as well as other organizational forms. Note that the physics preprint arXiv is arguably the most successful publisher in physics, yet is neither a conventional for-profit or not-for-profit organization.
[5] This drop in production and distribution costs is directly related to the current move toward open access publication of scientific papers. This movement is one of the first visible symptoms of the disruption of scientific publishing. Much more can and has been said about the impact of open access on publishing; rather than review that material, I refer you to the blog “Open Access News”, and in particular to Peter Suber’s overview of open access.
[6] In the first version of this essay I wrote that the existing services were “mediocre”. That’s wrong, and unfair: they’re very useful services. But there’s a lot of scope for improvement.
[7] After posting this essay, Christina Pikas pointed out that Web of Science and Scopus do have APIs. That’s my mistake, and something I didn’t know.
[8] There are also services where the primary problem is cultural barriers. But for the ideas I’ve described cultural barriers are only a small part of the problem.
Acknowledgments: Thanks to Jen Dodd and Ilya Grigorik for many enlightening discussions.
About this essay: This essay is based on a colloquium given June 11, 2009, at the American Physical Society Editorial Offices. Many thanks to the people at the APS for being great hosts, and for many stimulating conversations.
Further reading:
Some of the ideas explored in this essay are developed at greater length in my book Reinventing Discovery: The New Era of Networked Science.
You can subscribe to my blog here.
My account of how industries fail was influenced by and complements Clayton Christensen’s book “The Innovator’s Dilemma”. Three of my favourite blogs about the future of scientific communication are “Science in the Open”, “Open Access News” and “Common Knowledge”. Of course, there are many more excellent sources of information on this topic. A good source aggregating these many sources is the Science 2.0 room on FriendFeed.
Interesting, but unconvincing. STM publishing and newspapers (the straw man set up in the first half of the essay) are two very different things; the same rules do not necessarily apply. For instance:
1) The differences in income sources and relative financial health of STM publishing (I haven’t seen good figures for the past four years, but as of 2005 the field was seeing continued growth in income, in number of journals, and in readership. This puts it in a far different situation than newspaper publishing).
2) For scientists, the essential link between peer-reviewed publication and advancement in the sciences (this is why STM gets a steady stream of high-quality content – pretty much for free)
3) The role of peer review, which Michael dismisses in passing, but which is central to scientific publication.
Etc. Etc. Scientific publishing will certainly change, but I’m not at all certain it will be for the reasons Michael outlines here.
Nice job. Your discussion of local fitness maximums is reminiscent of current mathematical evolutionary theories. To my mind, the biggest issue will be the maintenance of quality in experimental design. I review a lot of crap in the medical and biological sciences and, in turn, often find reviews of my work, while sometimes anger inducing, to ultimately improve the quality of it. That aspect of scientific publishing must remain intact.
Interesting post, though I wonder if you feel that the disruptive process extends far beyond scientific publishing.
For example, if this is true for publishers, then is it also not true for universities as well? Considering the structural and financial pressures coming to bear on the sector at this time surely the same factors you discuss in the post apply here as well.
Certainly, like print newspapers, universities are not cheap and tend to the inflexible, wedded to specific models of organisation.
Thanks very much for this insightful post. I have commented in http://wwmm.ch.cam.ac.uk/blogs/murrayrust/?p=2166. One of the things I sense is the rapid increase of similar feelings within and around the discipline. Posts like yours act as landmarks in the shifting sands giving us courage to continue to explore new areas.
It is unfortunate that Universities do not have the leadership to take them through to a new optimum. They will have to make do with what the world provides by normal chaotic motion.
Good points. A clear line of thoughts.
One thing else to discuss are the obvious pitfalls of innovation.
The most evident of them is to ask a simple question: “how disseminated can the new product/service be, at this moment?”. Or, in other words, it is damn good but, will people use/learn it?
To illustrate, consider the Internet services for mobile phones. Greeeeeat idea! But at this early stages, internet server for mobile gadgets had nothing to do; no one was interested in migrating from their desktop to a tiny monochromatic display, with button-pushing based interaction.
One can think of an endless list of similar good-bad ideas.
@Michael, the process you describe has been underway in Chemistry for about five years; but in stealth mode. ChemSpider is but one high-profile example. For many more, check out:
http://zusammen.metamolecular.com/2009/03/09/sixty-four-free-chemistry-databases-serialized
I agree that innovation arising out of the technological advances in a ‘digital age’ will doubtless have an impact on current scientific publishing models.
A related issue is whether the scientific article is still the optimal format for disseminating scientific findings.
This is the focus of an event to be hosted at the British Library with John Wilbanks – if you’re interested please check out the forum:
Scientific findings in a digital world: What is the genuine article?
http://network.nature.com/groups/genuine_article/forum/topics
Very good article. I like the way you lay out reasons why incumbents have difficulty adopting new technologies. I’d add that many large incumbent scientifc publishers often have to innovate through acquistions because of the problems described above and because of constraints put on them by the financial markets (if they are public). Accounting for acquisitions allows companies more freedom to “buy” vs. “make”.
I totally agree about the need for scientific publishers (in fact, all publishers) to become proficient in IT. Technology is a key input to all content products & services; without constant innovation, publishers will get disrupted by new entrants. This relates to the article I posted last week, “Health Content is Rapidly Losing Its Value” on http://www.healthcontentadvisors.com/blog.
Michael
Just to clarify your query on the difference between different newspapers (my comment 21, your response, #43)
I meant to say that if you do a Google News search you implicitly do not care so much about the origin of that data. If you want to search news that appeared in the New York Times for example, you can do that there. That’s why I hardly use Google News myself.
For a lot of people looking for news the place of publication is perhaps becoming less relevant. In science publishing, the process and the relevance of journals is perhaps a little more driven by the author than the reader side, as in case of scientific journals an article is published in only one location, rather than main stream media who all cover the same big stories more or less. So in MSM readers vote with their feet, whereas in science publishing it is the authors? That’s perhaps one of the reasons the science publishing industry remains a slightly different case (for now).
But I am glad you find my comments on the paper-based format interesting, as I think in the long-term we may see quite some change coming from this direction!
Good stuff Michael … I suppose your theory would also apply to governments and their protectionist model of democracy, which explains a lot.
I recently participated in an “unconference” that brought together government wonks and Web 2.0 tech-types, and the discussion over a large part of the day revolved around disruption and the resistance to change even though change is inevitable. http://www.olyblog.com/f/09/VanChangeCampF06202009.shtml
We asked, “What is the new role of government?” and it’s too bad we weren’t aware of your thoughts here, because it would have added another dimension to the conversation.
It’s not unreasonable to suggest that this essay would be even better if its objectives, and its conclusions, were more radical.
The point is that the conclusions are not particularly novel. For example, we find the following account in Burgelman and Groves’ classic analysis of Intel’s decision-making process Strategy is Destiny:
and
In order to draw conclusions that are more novel, this essay (IMHO) needs to embrace objectives that are more radical.
Instead of predictive essays about the “future of science”, perhaps what is needed are prescriptive essays … because isn’t the future of science going to be something that we design and create (as individuals, and as communities, and as a planet)?
The idea that the future of science is something that will “just happen” seems (to me) to be inadequate to humanity’s urgent needs and pressing challenges. That is why I hope that Michael will consider including (at least some) explicitly prescriptive elements in The Future of Science.
Excellent post Michael, sums up the area well and in particular I found the organisational architectures section really useful for thinking about how change is affecting various industries.
I work for an agency in the UK called JISC (http://www.jisc.ac.uk) that is set up to support education and research in higher education by promoting innovation in new technologies.
We fund a lot of innovation projects in the area of scholarly communication, and it struck me reading the post how much of the work we are funding relates to the points you make in your article
We have funded 40 rapid innovation projects these are short agile projects that have just started and are designed to experiment and try out solutions to user problems, similar to start ups you mention in your post. A couple which sprang to mind as I read your post and are worth mentioning are a way to manage and publish data sets which uses a notecard metaphor: http://www.jisc.ac.uk/whatwedo/programmes/inf11/shuffl.aspx and a way to use bayesian filtering to help find journal articles of interest: http://www.jisc.ac.uk/whatwedo/programmes/inf11/personalisingalerts.aspx There are many more that are relevant to the areas you address in your article and you can read more about these projects at: http://code.google.com/p/jiscri/ as they develop over the next few months.
Thinking about scholarly communication models more generally, we have recently released a report which examined the economic implications of various models and found open access represents a better “local optimum”: http://www.jisc.ac.uk/news/stories/2009/01/houghton.aspx . We are discussing further work in this area with publishers designed to envisage the future for scholarly communications.
We have also been thinking about the preservation implications for blogs and funded a project called powr to study the preservation of web artefacts in general. This has lead on to a short project call archivepress to investigate using an installation of wordpress to preserve other blogs: http://jiscpowr.jiscinvolve.org/2009/06/24/archivepress-when-one-size-doesnt-fit-all/
Apologies that this has turned into a lengthy, link filled post but this is an exciting area to be involved in at the moment and developments are coming thick and fast.
As a follow-on to the above, the earliest essay on the topic of “the future of science” that I find in my database is Roberty Boyle’s 1641 essay The Sceptical Chymist, or Chymico-Physical Doubts & Paradoxes (which is freely) available on Project Guternberg.
The impact of Boyle’s then-radical views upon the general population is vividly rendered in Joseph Wright’s painting An Experiment on a Bird in the Air-Pump.
A singular advantage of studying Boyle and his essays is that we have 368 years of follow-up. 🙂
Thoroughly insightful and thought provoking. I follow many journalism-and-technology blogs and your analysis sliced to the heart of the matter more than most articles, especially the local optimum observation.
However, I disagree with “there’s no way you can get to that new optimum without passage through [hell].” There’s a well-established way for old media organizations to set up a base camp in the future: Establish a new media skunk works.
Basically, you equip one or more groups of your smartest people (and a few crazy smart ones) and push them off the local optimum cliff to see what new optimum they discover.
This has worked since the 1940s for “big iron” companies to break out of the mold. Lockheed used it to rapidly develop fighter planes. Motorola used it to develop their Razr cellphone. IBM used to develop the PC. Apple has used skunk works multiple times, first to develop the Mac and then the iPhone. See: http://www.economist.com/businessfinance/management/displaystory.cfm?story_id=11993055
Every big media company should be aggressively seeding the nearby ground with micro-ventures that extend their reach. Even if many fail, the one that succeeds will give them competitive advantage and hope for the future, as you suggested.
S. Jones – I’m in complete agreement. The Mac or (say) Nokia are very interesting and unusual cases where organizations did manage to reinvent themselves, using the approach you describe. So far as I know, that’s the only approach that works. However, the process is very hard on the organization — Nokia’s move from being primarily a rubber company to a telecommunications company was, obviously, not easy on their workforce. My understanding is that the Mac was also very tough on Apple internally, due to conflicts between old and new. This approach also requires the new venture to be thoroughly insulated from the old, otherwise it will be hard to resist the temptation to water down the new product to preserve the old business model.
Andy (#75): No apology necessary for the links – that’s exciting stuff!
Your take on scienfific publishing is insightful, but I’m sure not your analysis of the newspaper business is quite as on target.
My first issue is with the application of scientific theories/ideas to business and/or society. It sounds great to talk about immune systems, evolutionary behavior, chaos theory, local maxima, etc., but those analogies are almost never actionable in a non-scientific context. I wince, for example, when I think of the damage the book “The Tao of Physics” did to a generation of non-scientists by convincing them they a) understood quantum mechanics, and b) that it applied to or solved personal, spiritual and societal problems.
My second involves a big swing of Occam’s razor. Using complex scientific theories with catchy names to explain something as simple (and timeless) as the lifecycle of a business introduces unnecessary assumptions. Isn’t it as simple as this: successful businesses that have something to conserve (e.g. the NYT) act conservatively and startups with nothing to lose (TechCrunch) take big risks? The (very)few startups that succeed get big, end up with something to conserve, become conservative and then don’t take the risks required to dominate the next innovation cycle. And so it goes, over and over again.
I don’t think attaching sexy names to this process gives businesspeople any actionable insights, but it does sell books (evidence Mr. Gladwell and his blinking tipping points) and employ McKinsey consultants. I would moreover suggest that it actually does a disservice by confusing catch-phrases with understanding. To violate my own rule about using scientific analogies, it’s the difference betwen botany and biology.
Thanks Michael for an interesting and thought provoking article. Just a quick question. In today’s scientific community, grant funding works in concert with the publishing world using established ranking systems (Impact Factors) to score the researcher’s output and this in turn determines future support.
Once Pandora’s box has been opened what are the implications for the research assessment process? Is this one of the immune responses you mention? (Researchers will still need to play the existing system as they need funding.) In your vision of a much more ‘open’ world how will the research assessment be preformed in a rigorous and mutually acceptable way?
Well written, Michael. This is Clayton M. Christensen’s Disruptive Technology coming to the scientific publishing space.
Like Menedeley and others you mentioned, we hope we’re on the right side of this transition. Check us out, I’m one of the founders: http://www.pubget.com [Warning! shameless plug]
So far, no-one has commented upon what is arguably the most disruptive aspect of scientific publishing: the inexorable expansion of its scale.
How many scientific articles contain the word “insulin” in their title or abstract? A PubMed search presently finds 206,607 such articles —and the present publication rate stands at about 30 more articles per day.
How many biological molecules are as interesting as insulin? Surely more than 10^3 molecular species … presumably less than 10^8 … if we take the geometric mean of these bounds, we conclude that the scientific literature on biomedically interesting molecules will grow to the informatic equivalent of (say) 10^11 of today’s articles.
Let’s cost-out these research articles at 10^4 dollars each: the required net investment thus is about 10^15 dollars. Assuming a peaceful, prosperous planet with 10^10 people on it and a GDP of 10^4 dollars per capita, the total investment is about 10 years planetary GDP … which (when you thing about it) is a wonderfully prudent and economic investment! 🙂
Enterprises of this magnitude are (in my view) more than possibilities: their enabling technical foundations are in-place. Consequently there is a growing global appreciation that (to paraphrase George Marshall) “the ends are not yet clearly in sight but victory is certain”, that victory being (among other goals) a comprehensive understanding of our planetary biome.
The point of this essay is simple: people who think about the future of science should be thinking big—much bigger than than any previous century has thought. Because pretty obviously, there’s an exciting century ahead, for everyone.