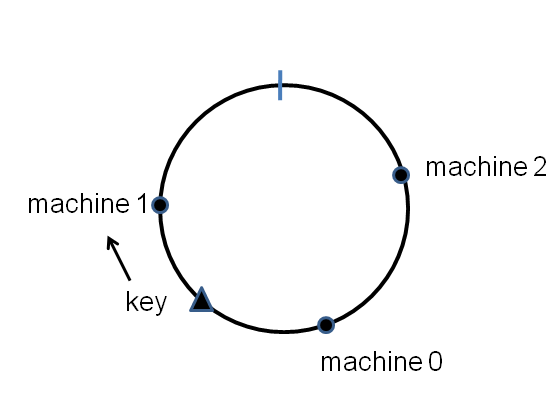
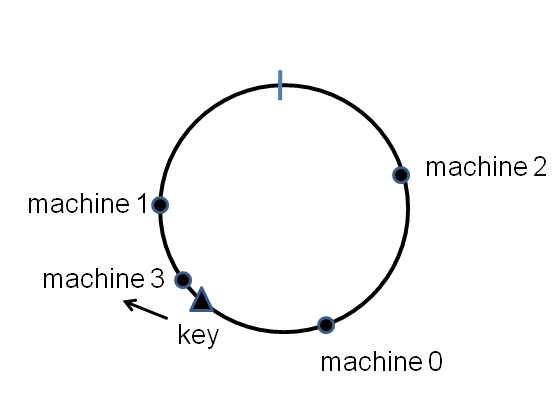
In my last post I described consistent hashing, a way of distributing a dictionary (i.e., a key-value store) across a cluster of computers so that the distribution of keys changes only slowly as machines are added or removed from the cluster. In this post I’ll describe a different scheme for consistent hashing, a scheme that seems to have some advantages over the scheme described last time. In particular, the new scheme is based on some very well-understood properties of the prime numbers, a fact which makes some properties of the new scheme easier to analyse, and gives us a great deal of fine control over the properties of this approach to consistent hashing. At the same time, the new scheme also has some disadvantages, notably, it will be slower for very large clusters.
So far as I know, the scheme for consistent hashing described in this post is novel. But I’m new to the subject, my reading in the area is limited, and it’s entirely possible, maybe likely, that the scheme is old news, has deep flaws, or is clearly superseded by a better approach. So all I know for sure is that the approach is new to me, and seems at least interesting enough to write up in a blog post. Comments and pointers to more recent work gladly accepted!
The consistent hashing scheme I’ll describe is easy to implement, but before describing it I’m going to start with some slightly simpler approaches which don’t quite work. Strictly speaking, you don’t need to understand these, and could skip ahead to the final scheme. But I think you’ll get more insight into why the final scheme works if you work through these earlier ideas first.
Let’s start by recalling the naive method for distributing keys across a cluster that I described in my last post: the key [tex]k[/tex] is sent to machine number [tex]\mbox{hash}(k) \mod n[/tex], where [tex]\mbox{hash}(\cdot)[/tex] is some hash function, and [tex]n[/tex] is the number of machines in the cluster. This method certainly distributes data evenly across the cluster, but has the problem that when machines are added or removed from the cluster, huge amounts of data get redistributed amongst the machines in the cluster. Consistent hashing is an approach to distributing data which also distributes data evenly, but has the additional property that when a machine is added or removed from the cluster the distribution of data changes only slightly.
Let’s modify the naive hashing scheme to get a scheme which requires less redistribution of data. Imagine we have a dictionary distributed across two machines using naive hashing, i.e., we compute [tex]\mbox{hash}(k) \mod 2[/tex], and distribute it to machine [tex]0[/tex] if the result is [tex]0[/tex], and to machine [tex]1[/tex] if the result is [tex]1[/tex]. Now we add a third machine to the cluster. We’ll redistribute data by computing [tex]\mbox{hash}(k) \mod 3[/tex], and moving any data for which this value is [tex]0[/tex] to the new machine. It should be easy to convince yourself (and is true, as we’ll prove later!) that one third of the data on both machines [tex]0[/tex] and [tex]1[/tex] will get moved to machine [tex]3[/tex]. So we end up with the data distributed evenly across the three machines and the redistribution step moves far less data around than in the naive approach.
The success of this approach suggests a general scheme for distributing keys across an [tex]n[/tex]-machine cluster. The scheme is to allocate the key [tex]k[/tex] to machine [tex]j[/tex], where [tex]j[/tex] is the largest value in the range [tex]0,\ldots,n-1[/tex] for which [tex]\mbox{hash}(k) \mod (j+1) = 0[/tex]. This scheme is certainly easy to implement. Unfortunately, while it works just fine for clusters of size [tex]n = 2[/tex] and [tex]n = 3[/tex], as we’ve seen, it breaks down when we add a fourth machine. To see why, let’s imagine that we’re expanding from three to four machines. So we imagine the keys are distributed across three machines, and then compute [tex]\mbox{hash}(k) \mod 4[/tex]. If the result is [tex]0[/tex], we move that key to machine [tex]3[/tex]. The problem is that any key for which [tex]\mbox{hash}(k) \mod 2 = 0[/tex] must also have [tex]\mbox{hash}(k) \mod 4 = 0[/tex]. That means that every single key on machine [tex]1[/tex] will necessarily get moved to machine [tex]3[/tex]! So we end up with an uneven distribution of keys across the cluster, not to mention needing to move a large fraction of our data around when doing the redistribution.
With a little thought it should be clear that the underlying problem here is that [tex]4[/tex] and [tex]2[/tex] have a common factor. This suggests a somewhat impractical way of resolving the problem: imagine you only allow clusters whose size is a prime number. That is, you allow clusters of size [tex]2, 3, 5, 7, 11[/tex], and so on, but not any of the sizes inbetween. You could then apply a similar scheme to that described above, but restricted to values of [tex]n[/tex] which are prime. More explicitly, suppose [tex]p_1 < p_2 < p_3 < \ldots < p_n[/tex] is an ascending sequence of primes. Let [tex]p_j[/tex] be the largest prime in this series for which [tex]\mbox{hash}(k) \mod p_j \geq p_{j-1}[/tex]. Then key [tex]k[/tex] is stored on machine [tex]\mbox{hash}(k) \mod p_j[/tex]. Note that we use the convention [tex]p_0 = 0[/tex] to decide which keys to store on machines [tex]0,\ldots,p_1-1[/tex]. Another way of understanding how this modified scheme works is to imagine that we have a cluster of size [tex]p[/tex] (a prime), and then add some more machines to expand the cluster to size [tex]q[/tex] (another prime). We redistribute the keys by computing [tex]\mbox{hash}(k) \mod q[/tex]. If this is in the range [tex]p,\ldots,q-1[/tex], then we move the key to machine number [tex]\mbox{hash}(k) \mod q[/tex]. Otherwise, the key stays where it is. It should be plausible (and we'll argue this in more detail below) that this results in the keys being redistributed evenly across the machines that have been added to the cluster. Furthermore, each of the machines that starts in the cluster contributes equally to the redistribution. The main difference from our earlier approach is that instead of looking for [tex]\mbox{hash}(k) \mod q = 0[/tex], we consider a range of values other than [tex]0[/tex], from [tex]p,\ldots,q-1[/tex]. But that difference is only a superficial matter of labelling, the underlying principle is the same. The reason this scheme works is because the values of [tex]\mbox{hash}(k) \mod p_j[/tex] behave as independent random variables for different primes [tex]p_j[/tex]. To state that a little more formally, we have: Theorem: Suppose [tex]X[/tex] is an integer-valued random variable uniformly distributed on the range [tex]0,\ldots,N[/tex]. Suppose [tex]p_1,\ldots,p_m[/tex] are distinct primes, all much smaller than [tex]N[/tex], and define [tex]X_j \equiv X \mod p_j[/tex]. Then in the limit as [tex]N[/tex] approaches [tex]\infty[/tex], the [tex]X_j[/tex] become independent random variables, with [tex]X_j[/tex] uniformly distributed on the range [tex]0,\ldots,p_j-1[/tex].
The proof of this theorem is an immediate consequence of the Chinese remainder theorem, and I’ll omit it. The theorem guarantees that when we extend the cluster to size [tex]q[/tex], a fraction [tex]1/q[/tex] of the keys on each of the existing machines is moved to each machine being added to the cluster. This results is both an even distribution of machines across the cluster, and the minimal possible redistribution of keys, which is exactly what we desired.
Obviously this hashing scheme for prime-sized clusters is too restrictive to be practical. Although primes occur quite often (roughly one in every [tex]\ln(n)[/tex] numbers near [tex]n[/tex] is prime), it’s still quite a restriction. And it’s going to make life more complicated on large clusters, where we’d like to make the scheme tolerant to machines dropping off the cluster.
Fortunately, there’s an extension of prime-sized hashing which does provide a consistent hashing scheme with all the properties we desire. Here it is. We choose primes [tex]p_0,p_1, \ldots[/tex], all greater than some large number [tex]M[/tex], say [tex]M = 10^9[/tex]. What matters about [tex]M[/tex] is that it be much larger than the largest number of computers we might ever want in the cluster. For each [tex]j[/tex] choose an integer [tex]t_j[/tex] so that:
[tex] \frac{t_j}{p_j} \approx \frac{1}{j+1}. [/tex]
Note that it is convenient to set [tex]t_0 = p_0[/tex]. Our consistent hashing procedure for [tex]n[/tex] machines is to send key [tex]k[/tex] to machine [tex]j[/tex], where [tex]j[/tex] is the largest value such that (a) [tex]j < n[/tex], and (b) [tex]\mbox{hash}(k) \mod p_j[/tex] is in the range [tex]0[/tex] through [tex]t_j-1[/tex]. Put another way, if we add another machine to an [tex]n[/tex]-machine cluster, then for each key [tex]k[/tex] we compute [tex]\mbox{hash}(k) \mod p_n[/tex], and redistribute any keys for which this value is in the range [tex]0[/tex] through [tex]t_n-1[/tex]. By the theorem above this is a fraction roughly [tex]1/(n+1)[/tex] of the keys. As a result, the keys are distributed evenly across the cluster, and the redistributed keys are drawn evenly from each machine in the existing cluster. Performance-wise, for large clusters this scheme is slower than the consistent hashing scheme described in my last post. The slowdown comes because the current scheme requires the computation of [tex]\mbox{hash}(k) \mod p_j[/tex] for [tex]n[/tex] different primes. By contrast, the earlier consistent hashing scheme used only a search of a sorted list of (typically) at most [tex]n^2[/tex] elements, which can be done in logarithmic time. On the other hand, modular arithmetic can be done very quickly, so I don't expect this to be a serious bottleneck, except for very large clusters. Analytically, the scheme in the current post seems to me to likely be preferable - results like the Chinese remainder theorem give us a lot of control over the solution of congruences, and this makes it very easy to understand the behaviour of this scheme and many natural variants. For instance, if some machines are bigger than others, it's easy to balance the load in proportion to machine capacity by changing the threshold numbers [tex]t_j[/tex]. This type of balancing can also be achieved using our earlier approach to consistent hashing, by changing the number of replica points, but the effect on things like the evenness of the distribution and redistribution of keys requires more work to analyse in that case. I'll finish this post as I finished the earlier post, by noting that there are many natural followup questions: what's the best way to cope with servers of different sizes; how to add and remove more than one machine at a time; how to cope with replication and fault-tolerance; how to migrate data when jobs are going on (including backups); and how best to backup a distributed dictionary, anyway? Hopefully it's easy to at least get started on answering these questions at this point. About this post: This is one in a series of posts about the Google Technology Stack – PageRank, MapReduce, and so on. The posts are summarized here, and there is FriendFeed room for the series here. You can subscribe to my blog to follow future posts in the series. If you’re in Waterloo, and would like to attend fortnightly meetups of a group that discusses the posts and other topics related to distributed computing and data mining, drop me an email at mn@michaelnielsen.org.